
Entropy vs Gini
Two Ways of Asking the Same Question

One of the confusing questions when I started learning Decision Trees was…
If Entropy and Gini almost always choose the same split in a decision tree, a very reasonable question arises — why do we even have two different metrics?
Why didn’t the community just settle on one and move on?
This confusion usually appears right when someone starts feeling comfortable with decision trees, and suddenly two unfamiliar formulas enter the picture, both claiming to measure something called impurity. The trick to understanding this comparison is to not start with formulas at all, but with what kind of question each metric is trying to answer.
Why Do We Measure Impurity in the First Place?
A decision tree grows by repeatedly asking simple questions like:
“Should I split the data based on feature X at value Y?”
To answer this, the tree needs a way to decide whether a split makes the data cleaner. Cleaner here simply means that the labels become more predictable after the split.
So impurity is not a complicated concept. It is just a measure of how mixed the classes are at a node.
A node with only one class → perfectly pure
A node with many classes mixed evenly → highly impure
Both Entropy and Gini exist to quantify this “mixed-ness”, but they look at it through slightly different mental lenses.
Entropy: Measuring Uncertainty
Entropy comes from information theory, but we do not need that background to understand its intuition.
Entropy is asking a very human question:
“How uncertain am I about the class label at this node?”
Imagine reaching a node in a tree and blindly picking a data point from it. If you have no idea what class it belongs to, entropy is high. If you can predict the class almost immediately, entropy is low.
Mathematically, entropy is written as:
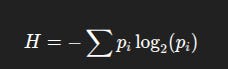
But instead of focusing on the formula, focus on the behaviour:
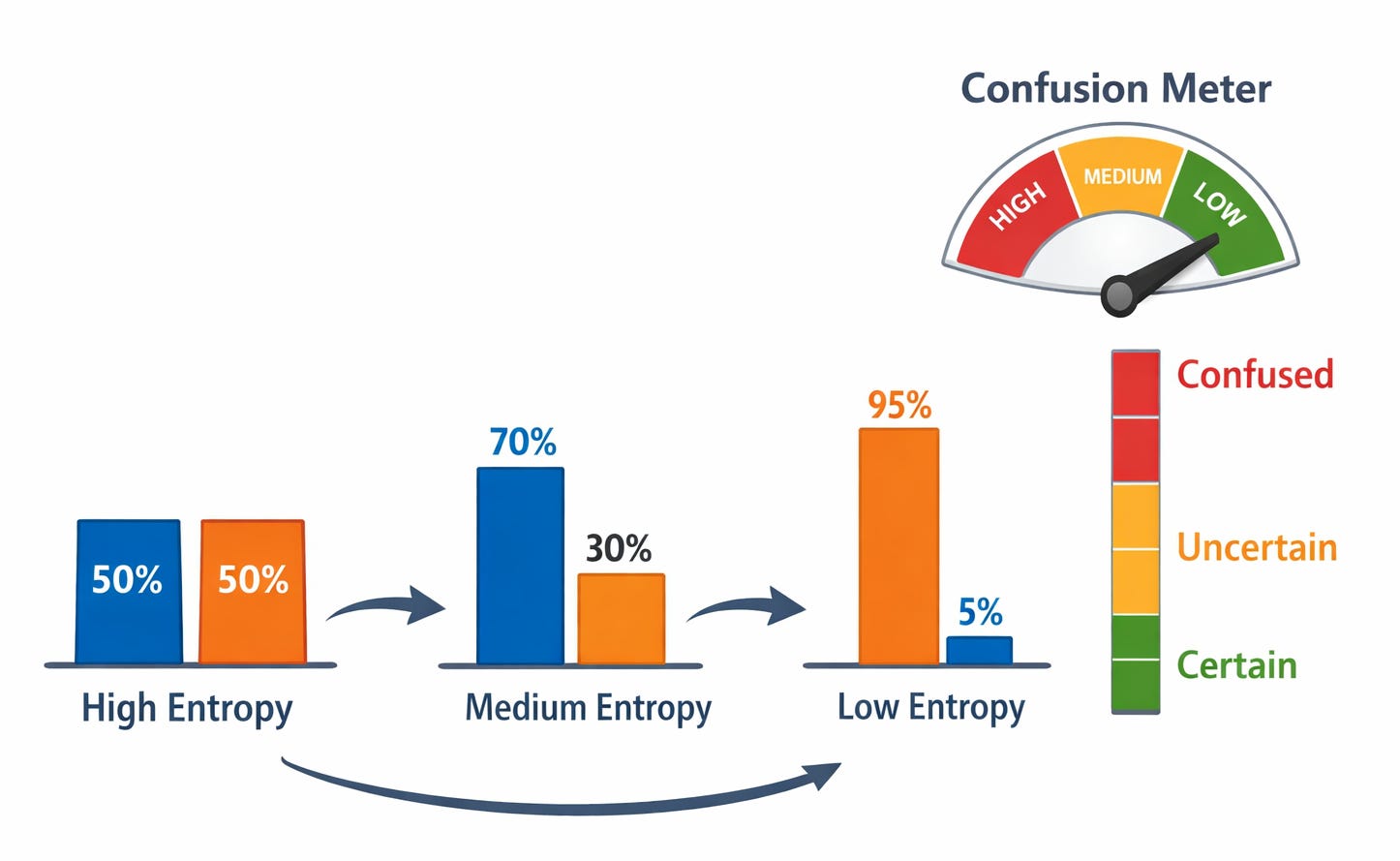
When all classes are equally likely → entropy is high
When one class dominates → entropy drops
When a node is perfectly pure → entropy becomes zero
Gini: Measuring Mistakes
Gini looks at the same situation, but asks a different question:
“If I randomly guess a class label according to the class distribution, how often would I be wrong?”
This framing is surprisingly powerful.
Instead of thinking about uncertainty, Gini thinks in terms of expected misclassification. It imagines a very lazy classifier that guesses labels based on proportions and asks how bad that strategy would be.
The Gini impurity is written as:
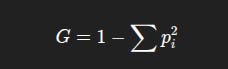
Again, intuition matters more than algebra:
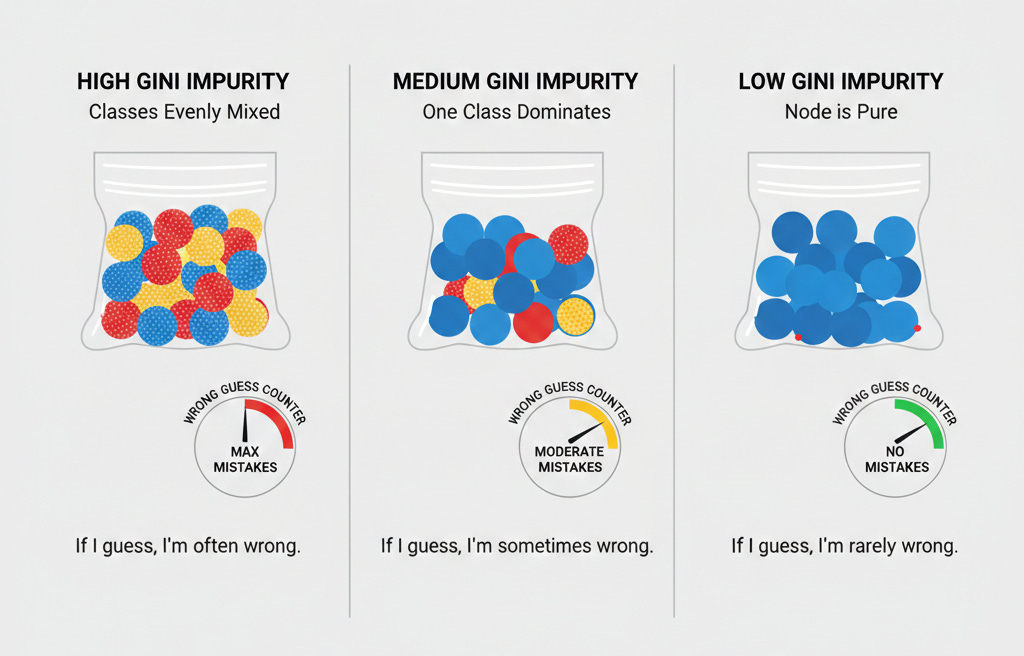
If one class dominates → squared probability is large → Gini is low
If classes are evenly mixed → squared probabilities are small → Gini is high
Pure node → Gini equals zero
A Single Running Example: The Bag of Balls
Let’s carry one example through the rest of the article.
Imagine a bag with balls of two colours.
Bag A
50 red
50 blue
Bag B
90 red
10 blue
From an entropy point of view:
Bag A is maximally confusing
Bag B is far less surprising
From a Gini point of view:
In Bag A, you will be wrong very often if you guess
In Bag B, guessing “red” almost always works
Same situation. Same conclusion.
Different thinking.
This is why most of the time both metrics rank splits in the same order.
Why Do Entropy and Gini Often Pick the Same Split?
This is one of the most important insights that is rarely stated clearly.
Decision trees do not care about the absolute value of impurity.
They only care about how much impurity is reduced by a split.
Both Entropy and Gini:
Reward purer child nodes
Penalize mixed distributions
Prefer balanced and meaningful splits
Since both functions are monotonic with respect to class purity, the relative improvement after a split is often ranked the same.
In simple terms:
The tree does not care how you measure impurity, as long as impurity goes down.
When Do They Actually Differ?
Although rare, there are situations where Entropy and Gini disagree.
This usually happens when:
Class distributions are highly skewed
There are many classes
The dataset is very small
Entropy is more sensitive to changes near probability extremes, meaning it reacts more strongly when rare classes appear or disappear. Gini, on the other hand, responds more smoothly.
So entropy may prefer splits that isolate rare classes slightly earlier, while Gini may stay conservative.
These differences are subtle, but they exist.
Why Most Libraries Default to Gini
If Entropy and Gini behave similarly, why does sklearn default to Gini?
The reason is refreshingly practical.
Gini is computationally cheaper (no logarithms)
Faster when building large trees
Empirically shows similar performance
In large-scale systems, these small efficiency gains add up, and since accuracy differences are negligible, Gini becomes the sensible default.
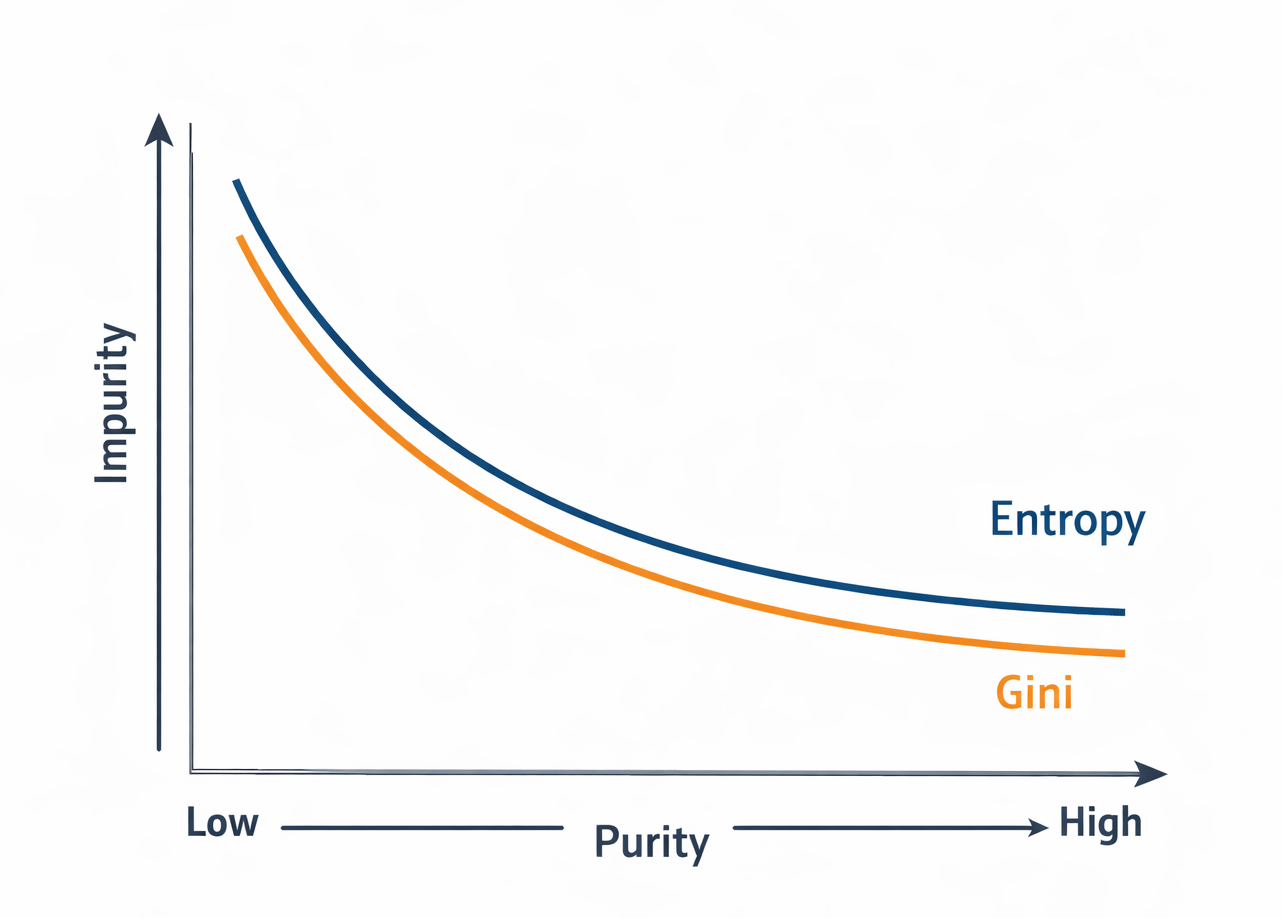
Visual Intuition Without Graphs
You can imagine the two metrics like this:
Entropy drops sharply as nodes become pure
Gini decreases in a smoother curve
Both reach zero at perfect purity
Entropy feels more “strict”, Gini feels more “forgiving”, but both guide the tree toward the same destination.
The Real Takeaway
Entropy and Gini are not rivals.
They are two languages describing the same idea.
Entropy talks about uncertainty
Gini talks about mistakes
Decision trees only care about improvement
Entropy measures how confused the model feels; Gini measures how often it would be wrong.
As long as impurity decreases, the tree is happy.
And once this intuition clicks, the formulas stop feeling intimidating — they just become tools expressing a very human idea: make decisions that reduce confusion
Hope this article gave you some insights into Entropy and Gini impurity and now-onwards, you guys won’t feel scared of these terms. See you in next article.
Till then, keep learning—and stay curious! and let the math settle naturally.
If this article helped clarify things, consider subscribing so you don’t miss future deep-dives, and feel free to like or leave a comment—I’d love to hear your thoughts and what you’d like to see next.